Summary
In this section, we will explore how partners do proper Continuity Engine designs. The goal of this is to (1) what considerations are needed to provide a Continuity Engine design, and (2) what methods make up solid design.
Introduction
As a presales and post sales engineer, you must be ready to do some design work for your prospects. In this Knowledgebase article, we will discuss what it takes to do just that. There are many things that need to be considered when designing a Continuity Engine deployment. Sure, the use cases are always straightforward, HA, DR and TERTIARY which seems easy on the surface but the devil is in the details. We will now discuss how to ensure that the design will be planned to meet the customers needs and avoid any confusion or worse delays in implementation.
Considerations
Networking
Making the decision on how you will setup the networking is one of the first decisions you as a Continuity Engine engineer will make. There are few approaches that need to be considered; an application with significant data changes or applications with little or no data changes. If the change rates are near zero such as a web server or an app server with no local data, the application can be configured to use a single network interface for both channel and public IP address on the same LAN segment. This provides a simple approach to building a cluster.
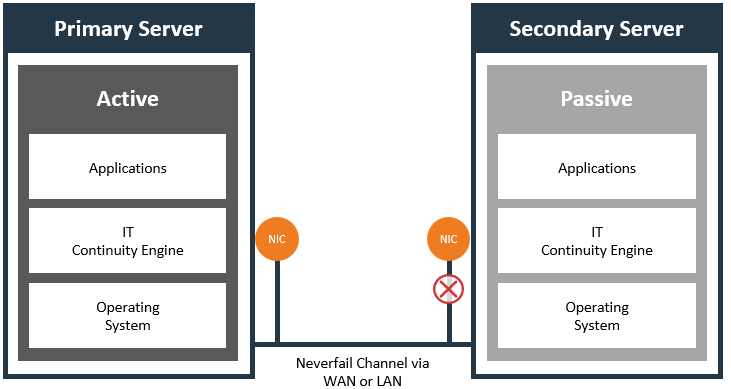
However, if the application has moderate to high change rates, a duel network configuration is the optimal approach. In this configuration, the channel is separated on to a different network interface. It is important to note that this can still use IP addresses on same LAN segment as the public IP address. However, many organizations choose to separate the replication traffic on to a replication vLAN. This can also be configured in Continuity Engine during the setup of the cluster in the "Add Standby Servers" wizard. This also works better as management IP addresses can also be segmented. Dual NIC configuration is the preferred method of deploying Continuity Engine and is considered a best practice.
LAN, WAN, Stretch Layer 2 Network
Continuity Engine supports a variety of network designs. This section talks about how Continuity works in each of these network configurations.
In most cases, HA is deployed in a local area (typically same datacenter, same subnet) where the primary method of an active and automatic failover deployment of Continuity Engine is enabled. HA locally is built on the premise that all the networking is (1) ultra-broadband, and (2) highly resilient. Continuity Engine also has intelligence built-in that can detect split-brain if the networking is interrupted. Many of Continuity Engines core features run over this channel connection such as application awareness, replication and service monitoring. This is the case when Continuity Engine deployments are setup in the same datacenter. Ideally, Neverfail recommends that each node be on a separate network switches, hosts (if virtual) and storage systems. They can technically span the same subnet if necessary. This ensures your local networking, hosts and storage are not single point of failure.
On the other hand in DR, the WAN is essential to Continuity Engine functioning properly. The WAN should be resilient to outages in DR mode. Continuity Engine is more tolerant of network outages (in DR mode) as long is automatic failover is NOT enabled (which is the default for DR). However, WAN connections must be sized for Continuity Engine traffic in order to maintain near zero RPO. If bandwidth is a big issue, WANSmart should be considered as part of a design for the prospect.
Stretch layer 2 WAN use case is a little more complex but with good planning and design , it will ensure a reliable Continuity Engine HA deployment. In this use case, prospects will typically have an application that does not support proper name resolution but rather uses an IP address and as such can not be changed. So with stretch layer 2, administrator's literally stretch a vLAN (subnet) between geographic site locations. Continuity Engine can support this network architecture, however there are some additional considerations that you will need to consider to ensure a successful implementation of Continuity Engine; these include the following:
- The WAN MUST be HIGHLY resilient. Prospects should have either a standby WAN connection that is triggered on failure or an active redundant WAN path to the DR site.
- If the WAN has an active redundant path to the DR site, Continuity Engine can use this path for the channel using different IP addresses other than the primary channel IP addresses. So if the primary WAN connection fails, Continuity Engine will switch to the alternate channel IP addresses to connect to the DR node without interruption.
- As a best practice, split-brain avoidance MUST be implemented in the Continuity Engine deployment.
In this diagram, notice how the IP addresses are managed between sites in a Continuity Engine deployment. Stretch layer 2 maintains the same vLAN across multiple sites that ensures proper HA performance.
PLEASE NOTE: In a stretch layer 2, if for some reason the WAN goes down, make sure the prospect is aware that each side needs to operate independently. Each side can not share resources! Continuity Engine's network monitoring will need to be configured on Primary and Secondary to ping resources that are physically local to it such as the domain controllers. This avoids split-brain. Split-brain can also be avoided by adding additional IP addresses if the WAN has active redundant paths to the DR site with Continuity Engine's server monitoring rules that ensures that the channel will continue to connect if the primary WAN connection is offline.
Avoid a Single Point of Failure
Its important to understand that Continuity Engine is superb at providing Continuous Availability but its only as good as the underlying compute and storage architecture. So here are some recommendations on how to avoid single points of failure in your designs:
- HA Mode (Local)
- Primary and Secondary should be on separate storage devices. If they are the same SAN, and the prospect experiences massive loss of their SAN, this will take down both Primary and Secondary.
- Primary and Secondary should be on different network switches if all possible. Failure of a network switch that both Primary and Secondary servers are plugged into can cause both systems to be disconnected from the network causing both ultimately to go passive to avoid split-brain.
- In a VMWare environment, make sure their is DRS affinity rules for both Primary and Secondary. Both should NOT reside on the same host in case the host fails. Optimally, you don't want any of the nodes to vMotion to other hosts as they are already redundant.
- Ensure the Primary and Secondary are not connected to the same SAN! This again is a single point of failure. These two should always be on separate storage devices to avoid both nodes freezing due to storage failure.
- HA Mode (Stretch Layer 2)
- The storage network should not run over the stretch layer 2 network which is connected to both Primary and Secondary. The loss of the stretched storage network could freeze both systems. Primary and Secondary as mentioned, should be on separate storage devices, connected locally on each datacenter.
- Engine should be configured to ping only resources in the local environment in network monitoring in order to ensure both Primary and Secondary can verify connectivity to each local network.
Name Resolution
As shown in the diagram above, in order to ensure the application can resolve the address of the DR node, a domain controller with a writable DNS server must be installed in the DR site. This is critical to the smooth transition during switchover and failover to the allow users and application to be able to access the recovered server at the DR site. How does it do this? At the time of failover, Continuity Engine on the DR node first assigns the IP address to the server and makes it available on the network. Then Continuity Engine's DNSUPDATE.EXE queries the local AD/DNS server for the "A" record and replaces it with a new record with a TTL of 45 seconds. It also queries for additional, writeable DNS servers in the environment. If it can reach them, it will change the "A" record on those DNS servers also making the failover transparent. All this happens by time the failover is complete in 30-90 seconds.
For prospects that do not have a DR site and are planning to build one, your prospects will need to add a DC with AD/DNS in the DR site. It also must be in the same domain that the protected application server is in.
Understanding Virtualization vs Physical Deployments
When designing a deployment, virtualization and physical server deployments are different. With virtualization the servers can easily be cloned regardless of the hypervisor. Most of the time it can be done interactively (a hot clone). Others requires the server to be shutdown and then cloned. In a VMWare environment, if the prospect is using a single vCenter, the prospect can perform a fully automated deployments using the EMS and vCenter. This is useful since Continuity Engine uses vCenter API's to complete the cloning process and is part of its orchestration process for deployment.
With any hypervisor, cloning is relatively simple. However, there will be times when you have limitations on how you can do your clone. These limitations are listed below:
- Production and DR site are security isolated.
- Hypervisor environments are managed separately (security isolated) in both sites.
- Data is to big to copy over the wire.
In these situations, you may need to clone locally and ship the virtual machine over to the DR site and import it back into the target environment. This must be added to the time of deployment.
In a physical environment, the cloning process is much different. It is recommended that the servers be identical if possible. This reduces the challenges associated with cloning with different server and hardware drivers. However, we realize this isn't always possible so ideally you want the secondary hardware to match up on processor speed, memory and storage configuration (logical volumes). This ensures that once the failover is completed, the active Secondary will perform at the same level as the production server.
The servers can be from different manufactures. Your prospect will need to make sure they have all the appropriate drivers for the Secondary server. Neverfail professional services uses the product by UBACKUP called
AOEMI. This product seems to work very well with
MOST physical server cloning and is free for the first 30 days. Of course, this adds time and complexity to the deployment so the prospect's expectation should be set that this will take more time to complete then deploying Continuity Engine with virtual machines.
Server Resources
In order to ensure a good design, you will have to assess the prospects environment. So you may want to ask the following questions:
- How old is your hypervisor environment?
- Do you have QOS rules in place to limit storage disk throughput?
- Do you over subscribe your CPUs on your host environment?
Understanding these will allow you to ascertain if Continuity Engine's design will even work or at a minimum perform properly in the prospects environment. If a customer has a hosts that are more than 5-7 years old, chances are Continuity Engine might experience some performance issues. QOS rules will dramatically reduce replication traffic and increase RPO. It also will make the full system check run much longer perhaps days instead of hours. Over subscription of compute resources can actually bog down a virtual server and cause lags and freezes of the server that would not be otherwise appear to the end user until you install Continuity Engine. This problem may have been there for years without the prospect even knowing. This can even cause many issues with replication and could cause Engine services to fail.
Security Isolated Environments
One of the biggest issues you will face is preparing your prospect for implementation in a security isolated environment or an applications that can not be connected to the internet. Many datacenters may limit how much access you have in terms of remote access into the target environment. In this case, boots on the ground may be required. However, there are few things the prospect will need to plan for to ensure a successful deployment and a solid design.
- PORT NUMBERS: The installation guide, in the section "Firewalls" lists all relevant port numbers. Also in the section "Firewall Configuration", this provides a diagram of the ports and how they communicate with each node in the cluster. This is essential for network professionals to setup firewall rules as it provides a visual representation of interconnections between each Continuity Engine component to make standing up the firewall rules much easier.
- HARDWARE PREP: With physical server deployments, some have found it beneficial to build the cluster before its sent into the datacenter. The hardware can then be racked up and with firewall rules defined, and systems can be deployed relatively quickly. In some cases, IP addressed can be assigned for the local environment before hand. Then the IP address configuration can be changed when the servers arrive onsite.
Its important that the customer understands these during the sales process so there is no surprises after the deal closes. Not properly communicating these could lead to major delays during implementation.
External Facing Applications
From time to time you will come across applications that are externally facing. These are usually web services providing services to users across the internet. In this use case, many find it challenging to repoint users to the application hosted now in a different datacenter. DNS propagation takes time and could seriously impact users getting access to the application after failover. This is where public dynamic DNS services comes in. There are services such as dyn.com and noip.com that provide external dynamic DNS. When the server fails over, the client software for
DYN or
NOIP are turned on and registers the new external IP address with their DNS service. The end result is that the users can connect to the DR active node within in seconds. This is a proven method to ensure users can get access to these types of applications quickly.
Bandwidth Estimations - What Takes Up
Bandwidth and Increases RPO
First, bandwidth requirements
depend on a range of different factors. Probably the biggest is change rates.
However, ancillary to this is available bandwidth at any one time or bandwidth
congestion. Change rates depend on the individual applications. For
example, the change rates will be much different (lower) for a web server then
a database server (much higher). So, planning bandwidth to get to the details
is about doing an analysis of change rates.
Second, it affects the RPO. With insufficient bandwidth your
send and receive queues will rise until the more bandwidth is available
increasing RPO which is what you don’t want. This shows the rise in a send and receive queue when there is high change rates and bandwidth might be slower.
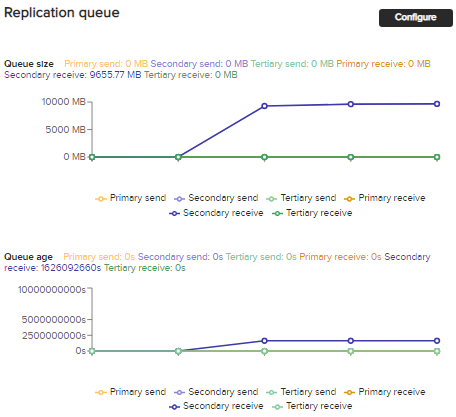
In addition, 100% saturation will result in dropped channel connections (very BAD).
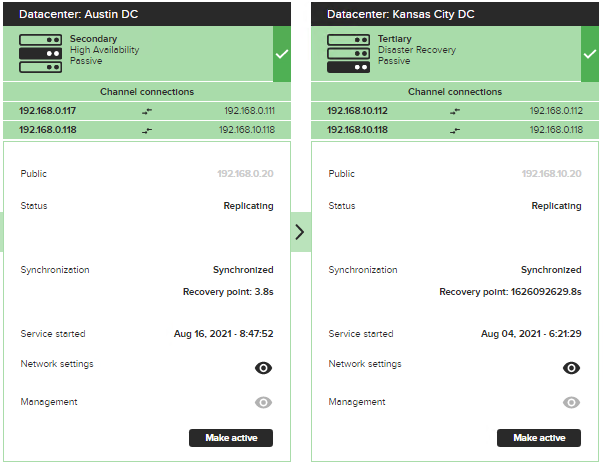
Here you can see the rise in the Recovery Point. Notice the
Tertiary. The numbers are much higher since the bandwidth to the DR site is
very low. Primary to Secondary its 3.8s which is quick considering there is
broadband in HA mode. These numbers will fluxuate depending on how much is
still in queue and available bandwidth and can change rapidly.
Other things affecting replication can be insufficient
compute and storage throughput bottlenecks which can make the send and receive
queue build up fast. The more they build up, the higher the RPO.
Bandwidth Estimations - How to Determine
Bandwidth Requirements
PS has a tool called SCOPE. It is installed on every node in
the cluster or can be downloaded and used as an analysis tool to measure change
rates and estimate bandwidth. I would recommend running it for a week. You
install it on the production server and configure it to send data over the WAN
to a target workstation with SCOPE installed. The SCOPE files can be sent to the Neverfail support team via ticket and they will
analyze it and give you some estimates.
Or you can use our best practices measurements. We typically
see that on average an application will take about 2.5Mbps of bandwidth or
10Mbps minimum whichever is larger of available bandwidth. This is good if you
scale up as multiple Neverfail protected applications will use the same shared
bandwidth. So, for example, if you have 1 protected application, 10Mbps is the
minimum. However, at scale, you have 10 protected applications, then you will
need (10x2.5Mbps) or 25Mbps minimum of available bandwidth minimum but certainly more would not hurt. This method
works for 95% of our deployments when asked.
If you want accurate numbers, then we would recommend you do
the analysis using SCOPE.
The good news is in low bandwidth, saturated bandwidth
situations WANSmart is optimal for this use case. It can reduce the network
replication up to 30x thus saving precious bandwidth. This is very helpful and works well most of the time but
not a miracle worker. If the bandwidth just isn’t there, it isn’t there
regardless if you reduce the load or not.
Therefore, set the right expectations. Provide the recommendations in your proposal so its not just conversation. This will ensure that if the prospect decides not to take your advice and upgrade their bandwidth to meet the load Continuity Engine will add to their WAN, you will have a defensible position in that you made the recommendations.
Design Methods
The Engine Management Service
Continuity Engine can not be deployed without a Engine Management Service (EMS). This management server can be installed on any non-protected Windows Server or Windows 10/11 desktop. However, the overhead is minimal (see the installation guide for details). This server will need to be planned for deployment. Keep in mind that deciding between Windows Server or Desktop is going to depend on how your prospect will use it. If there is only one person who manages the Continuity Engine deployment, they maybe fine with using a Windows desktop OS. With this OS, you cant share the portal service with others. This can only be done with Windows Server deployments of the EMS. Its a sharable portal service that uses AD authentication. The prospect must decide which approach will work best for them.
EMS allows users to first deploy Continuity Engine onto the Primary server. Then you go and run the "Add Standby Servers" function of Continuity Engine to extend the cluster to add additional nodes.
The "Add Standby Servers" wizard is the center piece of the deployment but it does need to require several additional information including the following:
- IP ADDRESSES: You will need IP addresses for the deployments included up to two public IP addresses and up to 6 channel IP addresses. You will need to know the subnet mask and DNS server for the DR standby server.
- NETWORK INTERFACES: You will need to know what network interface the public and channel will be deployed on.
- HOST AND DATASTORE: If deploying into a VMWare environment, you will need to know what host and datastore the Secondary and Tertiary the standby servers will be created on.
This information should be communicated to the prospect. This will give them time to make the decisions what IP addressed will be used and where the VMs will be hosted.
Conclusion
Deciding what topology is required for is only the beginning. Once the prospect gives you the topology, there is other considerations the need to be thought through in order to ensure you are providing the best information possible and that proper expectations are set during the sales process. This will also make it easier for your Professional Services team to do their job is the prospect not only knows what they are getting, but understands what's required of them to this into production.